😸 NEW from Open AI
OpenAI just unveiled o1, kicking off a new series of "reasoning" models designed to tackle complex questions faster than we... Product Hunt Read in browser This newsletter is brought to you
|
|
Read in browser

 |
This newsletter is brought to you by

|
|

OpenAI just unveiled o1, kicking off a new series of "reasoning" models designed to tackle complex questions faster than we can. They've also launched o1-mini, a smaller and more budget-friendly version. And yes, if you've been following AI buzz, this is the much-hyped Strawberry model everyone's been talking about.
This release is a big step toward OpenAI's goal of human-like artificial intelligence. Simply put, o1 outperforms previous models in writing code and solving tricky problems. But here's the catch: it's pricier and a bit slower than GPT-4o, so OpenAI is calling it a "preview" to highlight that it's still in the early days.
What's really interesting is how o1 was trained. Instead of just mimicking patterns from data, it uses reinforcement learning—learning through rewards and penalties—to figure things out on its own. It thinks in a "chain of thought," much like we do when solving problems step by step. OpenAI says it's more accurate and hallucinates less, though it's not perfect yet. This also makes for some great memes.
The standout feature? o1 tackles complex tasks like coding and math while explaining its reasoning. Ideally, this should make it more accurate. While I was playing around with the model this morning, I did notice a lot fewer hallucinations. It's a promising leap forward in AI, even if it's still ironing out some wrinkles and comes with a heftier price tag.

Earlier in the year, Apple lifted the lid on Apple Intelligence — the company’s heavily anticipated suite of AI features. In the original announcement, we got a taste of what was to come with things like generative emojis, Siri enhancements, and more.
Fast forward to today and Apple has revealed it’s newest range of iPhones and along with it some new features that will be powered by AI. Let’s dive in.
The new iPhones come with a new DSLR-style capture button for photos, videos, and settings adjustments. Stacked rear cameras support spatial video for Apple Vision Pro, and the A18 chip.
But the biggest update for the iPhone is arguably its integration with AI. With Apple Intelligence, you will be able to do things like detect real-world objects using the built-in camera, generate text based certain moods, and more easily filter through your photos by using the LLM technology.

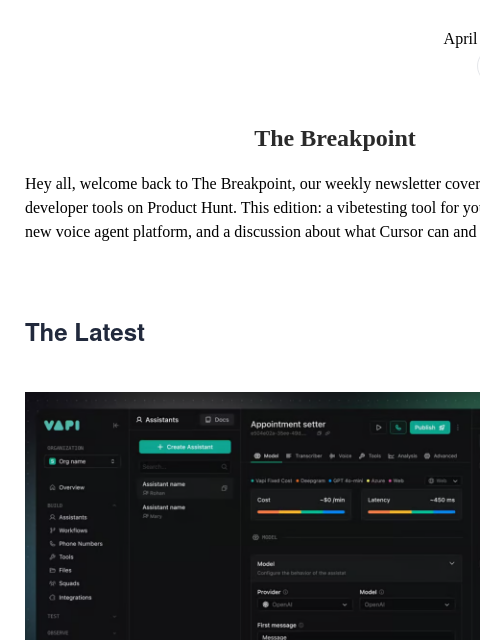
Redefine what’s possible with voice data—all on one seamless API that evolves ahead of the industry and handles the heavy lifting.
AssemblyAI offers:
The AI is the limit. Make sure you build on the best.

Replit, the billion-dollar IDE startup, has launched a new tool that makes going from idea to finished app as easy as typing a prompt.
Replit Agent isn’t just another run-of-the-mill coding copilot — it’s more like a junior software intern who can understand your goal and help bring it to life. It can understand natural language prompts and help create applications from scratch, making software development more accessible to users of all skill levels.
This isn’t anything particularly new on the surface. Do you remember Devin? The difference here is that Replit Agent can reason through a task and create its own steps to complete it — such as writing code, setting up environments, and managing deployments, rather than just taking a prompt and responding in code.
According to Replit CEO Amjad Masad, this isn’t about replacing developers but rather enabling developers of all skill levels to be more creative, saying, "We've crossed a threshold. This isn't about AI replacing developers. It's about supercharging human creativity and making software creation accessible to everyone.”
Latest Emails from producthunt
See moreproducthunt
2:49 PM (Yesterday)
Pitch us your products 👀 Product Hunt Friday, Apr 11 The Leaderboard Pitch us your products 👀 gm and welcome back to the Leaderboard. Today, we're looking at a publishing tool for voice memos, an

producthunt
Thu 2:49 PM
no more dinner fights 😌 Product Hunt Thursday, Apr 10 The Leaderboard no more dinner fights 😌 gm friends and welcome back to yet another edition of the Leaderboard. In today's issue, we've got:

producthunt
Wed 8:28 PM
Plus all of the launches you may have missed

producthunt
Wed 2:46 PM
Plus, how much should a founder really earn? Product Hunt Wednesday, Apr 09 The Leaderboard This newsletter was brought to you by Vanta Humans are so back 👀 goooood morning and welcome back to the
producthunt
Tue 9:11 PM
Plus, five AI tools you may have missed

producthunt
Tue 2:45 PM
Plus, get your product featured in this newsletter Product Hunt Tuesday, Apr 08 The Leaderboard This newsletter was brought to you by Vanta trinkets for vibecoders ✨ gooood morning legends and welcome
producthunt
Mon 2:51 PM
Plus, Amazon's newest AI Product Hunt Monday, Apr 07 The Leaderboard This newsletter was brought to you by Vanta Take back your eyeballs 👀 gm friends and welcome back to the Leaderboard. in

producthunt
Sun 2:47 PM
happy sunday 👀 Product Hunt Saturday, Apr 05 The Roundup This newsletter was brought to you by Vanta happy sunday 👀 gm and welcome back to your weekly roundup of all things tech, shipping, and
producthunt
Apr 3, 2025, 3:21 PM
Plus, a way to listen to music through your hands Product Hunt Thursday, Apr 03 The Leaderboard This newsletter was brought to you by Vanta robots, robots everywhere 🤖 Is that future of AI? I dunno but
producthunt
Apr 2, 2025, 9:02 PM
Plus all of the launches you may have missed